Managing PDF documents in a hybrid app for offline availability [Updated for MFP 7]
Etienne Noiret May 01, 2016
Adaters Java JSONStore MobileFirst_Platform




this article is a refreshed version of a previous article updated for IBM MobileFirst Platform 7.0. Indeed, the version 7.0 has introduced a new way to develop adapters using JAX-RS. Having the ability to use a Javascript or a Java based model gives the developer more flexibility to create optimized mobile services. Whilst each model has its own advantages, the particular use case described here is more elegantly implemented using the Java based approach.
It is a common requirement for a mobile app to give access to the end user to a set of documentation like PDF files, so that he can read them even when he is offline. This blog post explains how to manage documents metadata with the JSONStore, download documents from a remote location and read them locally.
Managing documents metadata
Depending on the number of documents to be downloaded and their size, it may be useful to manage which ones are already available, which ones have been downloaded, and thus only update those that are new or that changed since the last synchronization. Of course this is only possible if you have a service that can give you metadata about the files (but this is something usually available or at least easy to implement by reading a directory content in a file system).
For the purpose of this demonstration, we have implemented a Java adapter service that reads files from a root directory:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
@Path("/docs")
public class DocumentReaderResource {
static final String rootDirectory = "/users/enoiret/mydocs"; // Root path where documents are stored
FilenameFilter fileNameFilter = new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.toLowerCase().endsWith(".pdf");
}
};
@GET
@Produces(MediaType.APPLICATION_JSON)
@Path("/getDocList")
public JSONObject getDocumentList() {
JSONObject docList = new JSONObject();
JSONArray docs = new JSONArray();
File directory = new File(rootDirectory);
for(File f : directory.listFiles(fileNameFilter)) {
JSONObject doc = new JSONObject();
doc.put("name", f.getName());
doc.put("title", f.getName().substring(0, f.getName().length()-4));
doc.put("size", f.length()/1024); // get file size in kb
doc.put("timestamp", f.lastModified());
docs.add(doc);
}
docList.put("documents", docs);
docList.put("statusCode", 200);
return docList;
}
}
If the directory where the files are stored looks like this:

Then a call to the adapter will generate the following result:

On the client side, we need to initialize a JSONStore collection to hold these metadata:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var collections = {};
collections[collectionName] = {
searchFields : { name:"string", timestamp:"integer"},
};
//Initialize the document collection
WL.JSONStore.init(collections)
.then(function() {
documentsCollection = WL.JSONStore.get(collectionName);
documentsCollection.findAll({}).then(function (allDocs) { // If any document already available, display in the list
printList(allDocs);
});
})
.fail(function(errorObject) {
console.log("Failed to initialize collection");
});
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
var nbDocsFound;
var docsToUpdate;
var docsToAdd;
function getDocumentList() {
var request = new WLResourceRequest("/adapters/DocumentReader/docs/getDocList", WLResourceRequest.GET);
request.send()
.then(function (responseFromAdapter) {
// Handle adapter success
var data = JSON.parse(responseFromAdapter.responseText).documents;
// First check if some documents have their timestamp updated
nbDocsFound = data.length;
docsToUpdate = [];
docsToAdd = [];
data.forEach( function(doc) {
console.log("current doc "+doc.name);
doc.pdfLoaded = false;
documentsCollection.find({'name': doc.name}, {limit:1}).then(function (existingDocs) {
// This code is executed asynchronously (after the loop exits)
if(existingDocs.length==1) { // document already exists locally
if(existingDocs[0].json.timestamp!=doc.timestamp) { // document needs to be updated
console.log(doc.name + " is updated!");
docsToUpdate.push({_id: existingDocs[0]._id, json: doc});
}
} else if(existingDocs.length==0) { // document doesn't exist locally
console.log("adding document "+doc.name);
docsToAdd.push(doc);
}
displayUpdatedDocumentList();
});
});
})
.fail(function (errorObject) {
// Handle invokeProcedure failure.
});
}
function displayUpdatedDocumentList() {
if(--nbDocsFound) return; // Wait until all promises have been executed
console.log("after promises "+docsToAdd.length+":"+docsToUpdate.length);
updateDocs()
.then(function(numberOfDocumentsReplaced) {
console.log("Successfully updated "+numberOfDocumentsReplaced+" documents");
addDocs()
.then(function (numberOfDocumentsAdded) {
console.log("Successfully added "+numberOfDocumentsAdded+" documents");
documentsCollection.findAll({})
.then(function (allDocs) {
console.log("printing list");
printList(allDocs);
});
});
});
}
function updateDocs() {
if(docsToAdd.length>0) { // Add new items into collection
return documentsCollection.add(docsToAdd, {markDirty: false});
}
var dfd = new $.Deferred();
dfd.resolve(0);
return dfd.promise();
}
function addDocs() {
if(docsToUpdate.length>0) { // Update collection
return documentsCollection.replace(docsToUpdate, {markDirty: false});
}
var dfd = new $.Deferred();
dfd.resolve(0);
return dfd.promise();
}
function printList(allDocs) {
var ul = $('#docList'), doc, li;
ul.empty();
for (var i = 0; i < allDocs.length; i += 1) {
doc = allDocs[i].json;
// Create new <li> element
li = $('</li><li></li>');
var text = $('<span></span>').text(doc.title);
li.append(text);
var loadedText = doc.pdfLoaded ? "kb" : " (not downloaded)";
li.append('<div> ts: ' + doc.timestamp + ", size: "+ doc.size + loadedText + '</div>');
ul.append(li);
}
}
Notice that because of the asynchronous execution of some APIs, the code has been spread into several functions in order to ensure the consistency of the results stored and displayed.
From the app, an initial call to the getDocumentList() function (button "Refresh List") gives the following result:
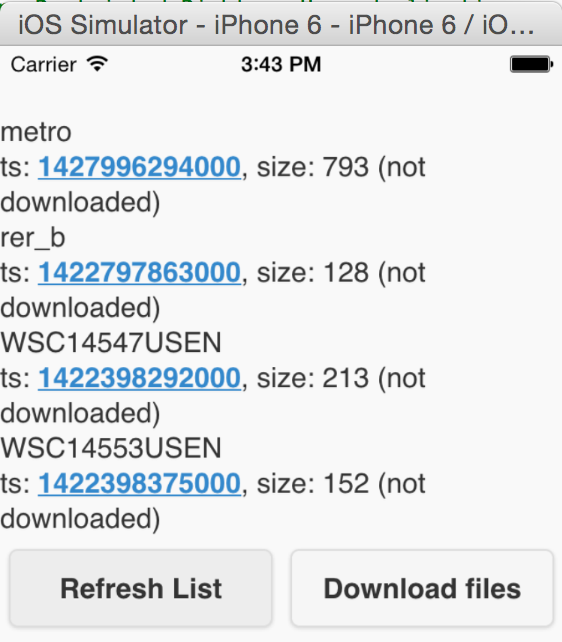
Lets say you download the initial set of documents (button "Download files", next chapter explains how it works). If you add a new file in the directory and update another one, a second call to the getDocumentList() function gives the following new result (notice the 2 files that are shown to be downloaded again):
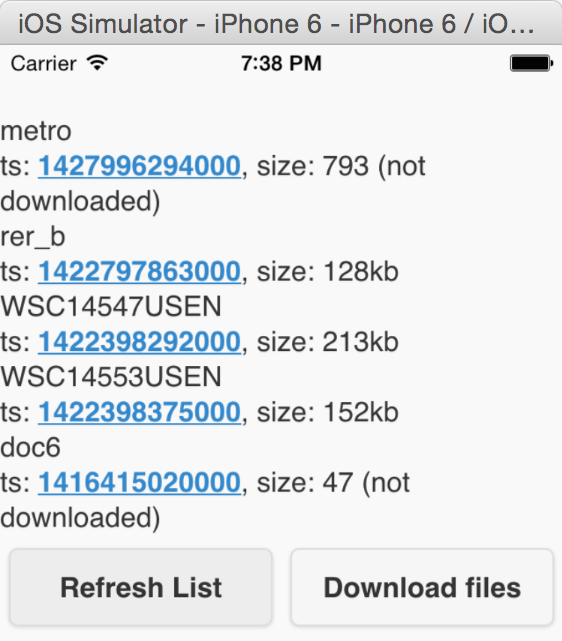
Downloading documents into the mobile app
Once we know which documents are available, the next step is to be able to download these locally. We will explore two options for downloading the documents.
Option 1: download the documents from a remote web server
This option is the easiest and preferred way to download the documents into the app. The following function is responsible for downloading an individual document:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//TODO: replace with URL of the web server where documents are located
var pdfRemoteUrl = "http://192.168.1.26:10080/MockService/";
function downloadDocument(docName) {
var localPath = getFilePath(docName);
var fileTransfer = new FileTransfer();
fileTransfer.download(
pdfRemoteUrl + docName, // remote file location
localPath, // where to store file locally
function (entry) {
console.log("download complete: " + entry.fullPath);
},
function (error) {
//Download abort errors or download failed errors
console.log("download error source " + error.source);
}
);
}
Notice here the hardcoded base URL of the remote server that should be calculated or dynamically retrieved in a real scenario. Notice also the getFilePath() function that calculates where the file should be stored. We'll see later why this is platform dependent.
In this sample, a downloadDocuments() function loops over the local metadata from the JSONStore and updates the pdfLoaded flag before redrawing the list with a link per line that gives access to each file downloaded:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
function downloadDocuments() {
documentsCollection.findAll({})
.then(function (allDocs) {
allDocs.forEach( function(jdoc) {
doc = jdoc.json;
if(!doc.pdfLoaded) {
downloadDocument(doc.name);
doc.pdfLoaded = true;
}
});
// update the collection
documentsCollection.replace(allDocs, {markDirty : false});
// redraw list
printList(allDocs);
})
.fail(function (errorObject) {
// Handle failure.
});
}
If you implement such a way to download documents, take advantage of the MobileFirst Platform security framework in order to secure the two servers but still provide a SSO between them.
Option 2: download the documents through an adapter service
In case option 1 is not possible, this option gives you the opportunity to get access to the files from the MFP server directly. I'd personally not recommend this way of doing since, as you'll see, it requires to encode and decode the documents which will lead to lower performance as their size increases. If the client app was a native app, then we could return directly a binary stream from the Java adapter. But Javascript in our case doesn't really gives the opportunity to work with binary data.
The adapter service is quite simple:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@GET
@Produces(MediaType.TEXT_PLAIN)
@Path("/getDocContent/{documentId}")
public String getDocumentContent(@PathParam("documentId") String documentId) throws IOException {
return getEncodedContent(rootDirectory+ "/" + documentId);
}
private static String getEncodedContent(String url) throws IOException {
byte[] buf = new byte[8192];
InputStream is = new FileInputStream(url);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int read = 0;
while ((read = is.read(buf, 0, buf.length)) > 0) {
bos.write(buf, 0, read);
}
bos.close();
is.close();
return Base64.encodeBase64String(bos.toByteArray());
}
Since the documents are downloaded differently, the downloadDocument() function on the client side needs of course to be updated accordingly:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
function downloadDocument(docName) {
var request = new WLResourceRequest("/adapters/DocumentReader/docs/getDocContent/"+docName, WLResourceRequest.GET);
request.send()
.then(function (response) {
// Handle invokeProcedure success: remove backslash character and decode binary data
var content = Base64Binary.decodeArrayBuffer(response.responseText.replace(/\\/g,"" ));
var localPath = getFilePath(docName);
function writeDocument(fileEntry) {
console.log("into file entry ",fileEntry.fullPath);
fileEntry.createWriter(
function (writer) {
console.log("before writing");
writer.onwriteend = function(evt) {
console.log("done written pdf "+docName);
};
writer.write(content);
},
fail);
};
// Write file on local system
window.resolveLocalFileSystemURL(
localPath.substring(0, localPath.lastIndexOf('/')), // retrieve directory
function(dirEntry) {
console.log("I am in directory "+dirEntry.fullPath);
dirEntry.getFile( // open new file in write mode
docName,
{create: true, exclusive: false},
writeDocument,
fail);
},
fail);
})
.fail(function (errorObject) {
// Handle invokeProcedure failure.
console.log("Failed to load pdf from adapter", errorObject);
});
}
Display a document from the mobile app
Once the documents are in the app, they can be displayed at any time, even when there is no connectivity.
The tricky thing here is that depending on the platform, you won't store the files at the same location. Indeed, iOS has a built-in PDF reader available for Safari, whilst for Android an external app is required to render the PDF. Therefore on Android it is important to store the files in a location that will be accessible from this app. In order to have a platform dependent implementation, the same function can be written specifically under its own platform, as shown in figure 3:
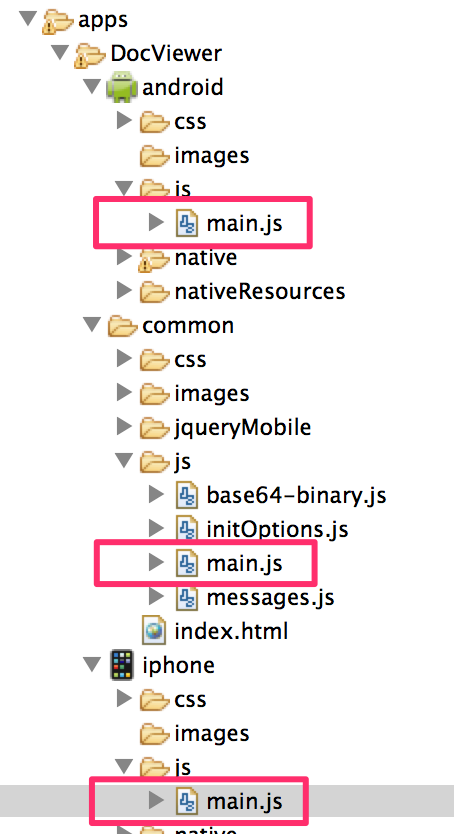
In the main.js file under the Android folder, the geFilePath() function is implemented as follow:
1
2
3
4
5
6
7
function getFilePath(fileName) {
console.log("external dir:"+cordova.file.externalDataDirectory);
return cordova.file.externalDataDirectory + fileName; // Works starting with MFP 6.3
}
function getTarget() {
return "_system";
}
Under the iPhone folder, the geFilePath() function has a different implementation:
1
2
3
4
5
6
function getFilePath(fileName) {
return ctx.fileSystem.root.toURL() + fileName;
}
function getTarget() {
return "_blank";
}
Finally, it is also needed to create the URL links properly on each platform in order to be able to launch the right PDF viewer:
1
2
3
4
5
6
7
8
9
$('#docList').on('click', 'li', function() {
var docLoaded = $(this).attr("doc_loaded")==="true";
if(docLoaded) {
var docName = $(this).attr("doc_name");
console.log("before trying to launch "+docName);
var localPath = getFilePath(docName);
window.open(localPath, getTarget(), "location=yes,hidden=no,closebuttoncaption=Close");
}
});
Figure 4 shows how it renders on iOS:
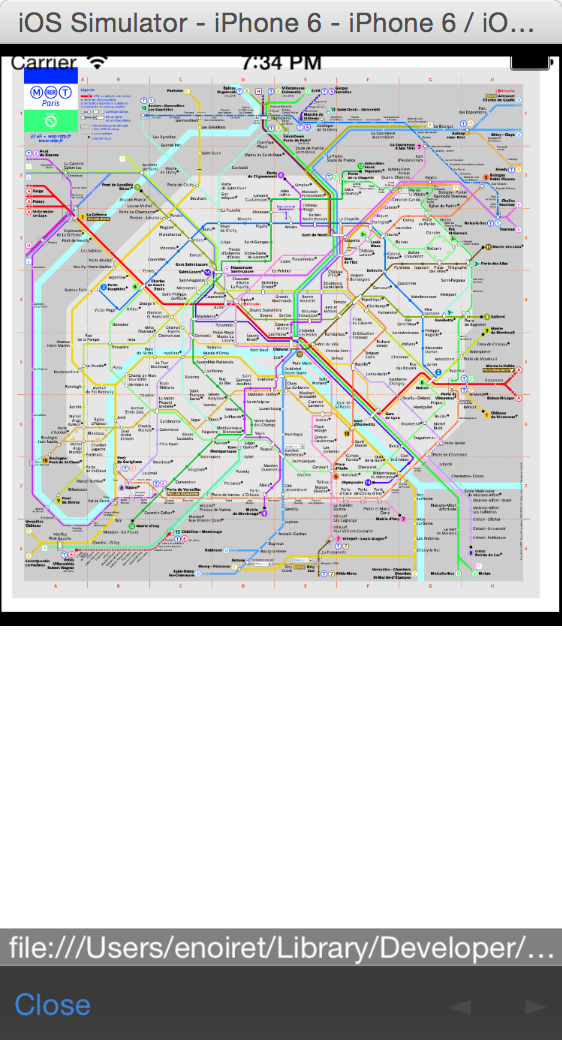
On Android it is necessary to hit the system back button to go from the PDF viewer app back to the hybrid app.
Use git clone https://hub.jazz.net/git/enoiret/MFPDocViewer if you want to download the sample project to make tests.
Inclusive terminology note: The Mobile First Platform team is making changes to support the IBM® initiative to replace racially biased and other discriminatory language in our code and content with more inclusive language. While IBM values the use of inclusive language, terms that are outside of IBM's direct influence are sometimes required for the sake of maintaining user understanding. As other industry leaders join IBM in embracing the use of inclusive language, IBM will continue to update the documentation to reflect those changes.