Procedimientos recomendados para configurar el clúster de producción de MobileFirst Analytics
improve this page | report issueVisión general
En este tema se describe la lista de procedimientos recomendados que se deben seguir a la hora de configurar un servidor de Analytics, incluido lo que se debe y no se debe hacer.
MobileFirst Analytics Server - Valores de configuración
Se debe aplicar depuración de datos al entorno de producción, de forma obligatoria, para no hacer persistente todo el conjunto de documentos desde el principio. El ámbito de búsqueda de las consultas de Elasticsearch se puede reducir de forma considerable definiendo los valores adecuados de TTL para los diferentes documentos de sucesos. A continuación, se muestran los valores de TTL que se deben definir para MobileFirst Analytics v8.0 Server:
Propiedades de TTL para sucesos/documentos de Analytics
- TTL_PushNotification
- TTL_PushSubscriptionSummarizedHourly
- TTL_ServerLog
- TTL_AppLog
- TTL_NetworkTransaction
- TTL_AppSession
- TTL_AppSessionSummarizedHourly
- TTL_NetworkTransactionSummarizedHourly
- TTL_CustomData
- TTL_AppPushAction
- TTL_AppPushActionSummarizedHourly
- TTL_PushSubscription
Ejemplo de uso:
<jndiEntry jndiName="analytics/TTL_AppLog" value= '"20d"' />
El valor de TTL esperado son literales de serie y se debe pasar entre comillas simples.
MobileFirst Analytics Server - Topología
Clúster de analíticas de varios nodos
- Es importante disponer de un equilibrador de carga frente a los nodos para asegurarse de que se ofrece una carga uniforme a la capa de analíticas entre los nodos.
- En un clúster de analíticas de dos nodos, cuando no se utiliza un equilibrador de carga, es recomendable configurar o utilizar la consola de Analytics del nodo que no se utiliza para aceptar los datos de MobileFirst Server.
Por ejemplo:
Supongamos que hay dos nodos para el servidor de analíticas. En ese caso, la recomendación para la configuración de MobileFirst Server para las analíticas es la siguiente:
Recomendado:
mfp.analytics.url -> http://node1:9080/analytics-service/rest
mfp.analytics.console.url -> http://node2:9080/analytic/console
NO recomendado:
mfp.analytics.url -> http://node1:9080/analytics-service/rest
mfp.analytics.console.url -> http://node1:9080/analytic/console
De esta forma, el usuario puede reducir la carga en los nodos cuando ve la consola de analíticas.
MobileFirst Analytics Server - Ajuste de rendimiento
Ajuste del sistema operativo
- Aumentar el número permitido de descriptores de archivos abiertos de 32k a 64k.
- Aumentar los recuentos de correlación de memoria virtual.
Nota: compruebe la documentación correspondiente para el sistema operativo.
Ajuste del servidor de aplicaciones
Si utiliza un perfil de Liberty de WebSphere Application Server v8.5.5.6 o versiones anteriores, asegúrese de ajustar explícitamente los valores de tamaño de JVM Thread Pool.
Como resultado de este comportamiento, muchos usuarios definían el valor de coreThreads del ejecutor en un número elevado para asegurarse de que el ejecutor nunca llegase a punto muerto. Sin embargo, en v8.5.5.6, el algoritmo de ajuste automático se ha modificado para evitar los puntos muertos con determinación. Ahora es casi imposible que el ejecutor llegue a un punto muerto, de forma que, si anteriormente ha definido coreThreads manualmente para evitar los puntos muertos del ejecutor, quizá quiera volver al valor predeterminado una vez que pase a utilizar v8.5.5.6.
Ejemplo:
<executor name="LargeThreadPool" id="default" coreThreads="200" maxThreads="400" keepAlive="60s" stealPolicy="STRICT" rejectedWorkPolicy="CALLER_RUNS"/>
Ajuste de analíticas
- Se tiene que definir el mismo valor (mínimo y máximo) en Java Xms y Xmx.
- Tamaño de almacenamiento dinámico máximo permitido por JVM <= Tamaño de RAM/2.
- Número de fragmentos primarios = Número de nodos del clúster de analíticas.
- Número de réplicas por fragmento >= 2.
Nota: si solo hay un nodo, no hay necesidad de tener una réplica.
Ajuste de Elasticsearch
El ajuste de Elasticsearch se puede realizar en un archivo YAML independiente (por ejemplo, se puede denominar elasticsearchconfig.yml), y la vía de acceso a este archivo se puede configurar en la configuración del servidor de analíticas (mediante las propiedades JNDI).
Nombre de propiedad: analytics/settingspath
Valor: <path_to_the_ES_config_yml>
Aplique los parámetros de ajuste de Elasticsearch añadiendo los valores a un archivo .yml y acceda a él mediante la entrada de JNDI.
Los parámetros de ajuste de Elasticsearch se deben tener en cuenta para un ajuste básico del entorno y se pueden ajustar más en función de los recursos de infraestructura:
-
Defina un valor para indices.fielddata.cache.size
Por ejemplo:
indices.fielddata.cache.size: 35%Nota: utilice analytics/indices.fielddata.cache.size con precaución. No lo aumente a un valor mayor, puesto que aumentar este valor puede producir un error OutofMemory. La tecnología subyacente que utiliza la plataforma de analíticas carga varios valores de archivo en la memoria para proporcionar un acceso más rápido a dichos documentos. Esto se conoce como memoria caché de campo. De forma predeterminada, la cantidad de datos que la memoria caché de campo carga en la memoria no tiene límite. Si la memoria caché de campo llega a ser demasiado grande, se puede producir una excepción de falta de memoria y la plataforma de analíticas se puede bloquear.
-
Defina un valor para indices.fielddata.breaker.limit.
Defina indices.fielddata.breaker.limit en un valor mayor que indices.fielddata.cache.size.
De modo que, si el tamaño de memoria caché es 35%, debe definir el límite de interruptor en un valor mayor que el tamaño de memoria caché.
-
Defina un valor para indices.fielddata.cache.expire.
Este valor define la hora de caducidad de la memoria caché de Elasticsearch y evita que la memoria caché crezca de forma ilimitada y agote el almacenamiento dinámico.
indices.fielddata.cache.expire
Un valor basado en tiempo que hace que caduquen los datos de campo tras un determinado periodo de inactividad. El valor predeterminado es -1. Por ejemplo, se puede definir en 5 m para una caducidad de 5 minutos.
-
El valor predeterminado de Analytics es NO depurar ningún dato.
Configure el TTL como corresponda para asegurarse de que se depuren los datos. De lo contrario, el almacén de datos podría crecer de forma ilimitada.
MobileFirst Analytics Server - Lo que se debe y no se debe hacer
- No borre el directorio analyticsData cuando se estén ejecutando los nodos de analíticas.
- En un clúster de varios nodos, no utilice el mismo nodo para enviar los sucesos por push al clúster de analíticas y acceder a la consola. El procedimiento recomendado es utilizar un equilibrador de carga frente al clúster de analíticas.
- No utilice otras metodologías de clúster de servidores de aplicaciones para el clúster de analíticas. El proceso de Elasticsearch subyacente crea un clúster por su cuenta mediante sus mecanismos de descubrimiento de nodos.
- No utilice Open JDK (o Sun Java) para Analytics en el perfil completo de IBM WebSphere Application Server o en IBM WebSphere Application Server Network Deployment.
- En ningún caso aumente el tamaño de almacenamiento dinámico mínimo/máximo de analíticas a un valor mayor que la mitad del tamaño de RAM en el nodo. Por ejemplo, si tiene un nodo con un tamaño de RAM de 16 GB, entonces el tamaño de almacenamiento dinámico máximo permitido es de 8 GB para las analíticas.
- Para el nombre de clúster de analíticas (propiedad JNDI analytics/clustername), utilice un nombre de clúster exclusivo. No utilice el nombre predeterminado worklight.
MobileFirst Analytics Server - Problemas de SDK
1. Las aplicaciones Cordova se deben inicializar en una plataforma nativa para sucesos de ciclo de vida para habilitar la captura de AppSession
En MobileFirst Platform Foundation v8.0, las sesiones de aplicaciones se incrementan/graban cuando la aplicación se traslada desde el segundo plano al primer plano.
La captura de AppSessions se habilita añadiendo escuchas para los sucesos de ciclo de vida. Los SDK nativos proporcionan API adecuadas para añadir estos escuchas. Sin embargo, en el caso de Cordova, no hay ninguna API de JavaScript para añadir estos escuchas de sucesos de ciclo de vida. En su lugar, los escuchas se tienen que añadir mediante API de plataformas nativas, incluso para las aplicaciones Cordova.
Extracto de la documentación:
Una vez que configurado el SDK de analíticas, las sesiones de la aplicación empiezan a ser grabadas en el dispositivo del usuario. Se graba una sesión en MobileFirst Analytics cuando la aplicación se pasa desde el primer plano al segundo plano, lo que crea una sesión en Analytics Console. Tan pronto como el dispositivo está configurado para registrar sesiones y envía los datos, puede ver Analytics Console cumplimentado con datos, tal como se muestra a continuación.
Por ejemplo, para una aplicación Cordova en la plataforma iOS (iOS), es obligatorio añadir lo siguiente bajo AppDelegate.m:
[[WLAnalytics sharedInstance] addDeviceEventListener:LIFECYCLE];
[[WLAnalytics sharedInstance] send];
2. Ver los datos personalizados en Analytics Console
Para localizar rápidamente los datos personalizados enviados al servidor de analíticas mediante las API del SDK de cliente de Analytics, se deben seguir estos pasos.
Vaya a Analytics Console > Panel de control > Gráficos personalizados > Crear un gráfico personalizado
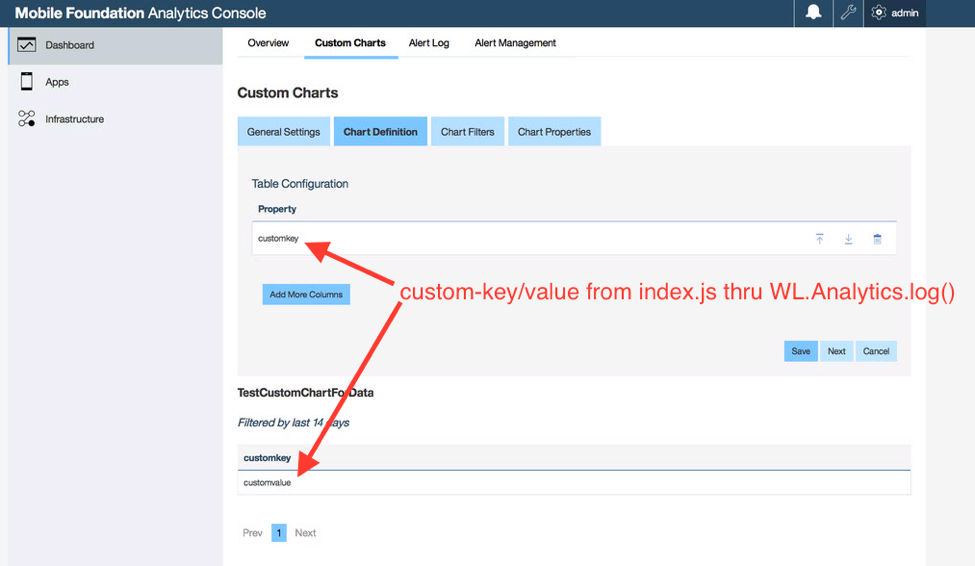
Para obtener más información, consulte la documentación aquí.
MobileFirst Analytics Server - Pasos de resolución de problemas
- Versión de entorno de cliente:
Recopile los detalles de toda la pila de software, incluido el SO, el JDK/JRE, el servidor de aplicaciones, la versión de MobileFirst Platform Foundation y la versión de la compilación de MobileFirst Platform Foundation. - Compare los detalles del entorno con los requisitos/la matriz de compatibilidad de software de IBM MobileFirst Analytics.
- Recopile las especificaciones utilizadas de hardware y topología de Analytics.
- Compruebe si se ha realizado algún ajuste de rendimiento (en el caso de los problemas de rendimiento).
- Recopile las entradas/propiedades del archivo
server.xmlde MobileFirst Platform Foundation Server (Liberty) y del entorno JNDI (ND/perfil completo de WAS) para verificar la configuración de la integración de Analytics. - Recopile la captura de pantalla de la consola de administración de Analytics.
- Recopile las entradas/propiedades del archivo
server.xmlde Analytics (Liberty) y del entorno JNDI (ND/perfil completo de WAS) para verificar la configuración de la integración de Analytics. - Recopile la salida de las API REST siguientes (enumeradas bajo la sección – Mandatos importantes y API para resolución de problemas de analíticas).
Programas de utilidad para resolución de problemas
A continuación, se enumeran las herramientas de código abierto que pueden resultar eficaces para visualizar y administrar los índices de elasticsearch, la asignación de fragmentos/datos, etc.
Mandatos importantes y API para resolución de problemas de analíticas
Utilice cURL para ejecutar las API REST siguientes para capturar la respuesta para identificar información diversa sobre el clúster/el fragmento/los índices:
http://<es_node>:9500/_cluster/health
http://<es_node>:9500/_cluster/stats
http://<es_node>:9500/_cat/shards
http://<es_node>:9500/_node/status
http://<es_node>:9500/_cat/indices
Referencias
- MobileFirst Analytics - Clústeres rápidos y “sucios”
- MobileFirst Analytics - Planificación para la producción
- MobileFirst Analytics – Guía de instalación
- Definición del valor de la propiedad JNDI para el TTL (Time To Live) de Mobile Analytics como días en el perfil de Liberty
Inclusive terminology note: The Mobile First Platform team is making changes to support the IBM® initiative to replace racially biased and other discriminatory language in our code and content with more inclusive language. While IBM values the use of inclusive language, terms that are outside of IBM's direct influence are sometimes required for the sake of maintaining user understanding. As other industry leaders join IBM in embracing the use of inclusive language, IBM will continue to update the documentation to reflect those changes.