Stretching product topologies to delight customers
Maurizio Luinetti January 26, 2017
MobileFirst_Platform zero_downtime




Maurizio Luinetti is an Executive Architect for IBM Software providing technical leadership and driving client adoption of IBM architectures, designing and proposing innovative solutions that address client business goals linking together software capabilities and strategic initiatives and coordinating several specialists from different business units.
Overview
For the banking industry, the customer interaction through the mobile channel is predicted to be the prevalent one in the near future. So banks are demanding topologies that allow to achieve a near-zero downtime target. Tailoring the appropriate product topology, IBM MobileFirst Platform Foundation is able to achieve this stringent target. And to delight your clients, you have to satisfy the unexpressed requirements too.
Stretching product topologies to delight customer
I work as an IT architect for a large financial institution and I’m very often challenged to satisfy sophisticated business requirements with the current infrastructure (or with minimum enhancement to it to reduce implementation costs).
Recently, I was asked by my customer to enhance the current topology serving their mobile banking channel, based on IBM MobileFirst Platform Foundation v7.x (MFPF), to achieve a near-zero downtime target. I think this is (or will be in the near future) a common requirement due to the increasing importance of the customer direct channels in the banking industry and the fact that the mobile channel is predicted to be the prevalent one in the near future. This business requirement poses stringent requests both to the application architecture and to the infrastructure topology, and I cannot start from scratch as if I were in a greenfield project.
The degrees of freedom I had were limited by many factors:
- The current archetype used by the customer for all the WebSphere Application Server (WAS) based products and applications: a 4-nodes geographically dispersed single WAS cell spanning over 4 sites in 2 campuses.
- The application life cycle management tool in use
- The current infrastructure management procedures
- Besides, it is requested to implement MFPF Operational Analytics component to perform analysis about events that are collected from devices, apps, and servers for patterns, problems, and platform usage statistics
- Last but not least, I had to provide a solution that is fully supported by the product.
First, I had to master the product the customer is using. The MFPF runtime environment is a mobile-optimized server-side component that runs the server side of mobile applications (back-end integration, version management, security, unified push notification). Each runtime environment is packaged as a web application (WAR file) and can host one or more MobileFirst applications. Each runtime environment requires a database to host information such as the list of devices that connect to it. Different runtime environments cannot share database tables. If there are multiple runtime environments, the tables must be in different schemas or different databases. Similar runtime environments that run in the same cluster of farm must use the same database unless you implement a disaster recovery topology with replication and conflict management.
Then, I had to analyze the MFPF v7.x supported topologies to verify if one of them could satisfy the business requirement I am confronted with. MFPF supports many different topologies, from the trivial stand-alone server one to very sophisticated topologies used to provide business continuity.
- Server farm: A farm is a set of individual servers where the same components are deployed and where the same administration database and runtime database are shared between the servers
- WAS Network Deployment: The administration components and the runtimes are deployed in clusters of the WAS cell. Multiple modes are available to deploy the administration components and the runtimes.
- Active-active disaster recovery: It involves several instances of MFPF deployed in two or more active sites in combinations with IBM Cloudant database and optionally WebSphere eXtreme scale (WXS). A prerequisite for enabling this topology is to operate MFPF in session-independent mode.
- Disaster recovery site: MFPF supports the creation of a second site that becomes operational if the first site is down. The architecture of the second site is a copy of the first site and, for the backup site to work, data on the first site must be mirrored to the second one. The mirror frequency depends on the foreseen usage of the second site. When you switch to the second site, some information might be lost (e.g. all clients lose context and disconnect, and in case of authenticated apps, the user is prompted to log in again). Before you switch back to the first site, you must mirror the database back to the first site.
Despite their name that strikes fear, the last two topologies could be used for any scope (a “disaster” could be deliberate, e.g. a server could be switched off to perform planned maintenance).
None of the above topologies seems to fulfill the business requirement I had, but a deeper analysis on the “disaster recovery site” one allow me to find the right solution for the customer. The “active-active disaster recovery” topology was interesting, but was not compliant with the previously mentioned constraints on the topology.
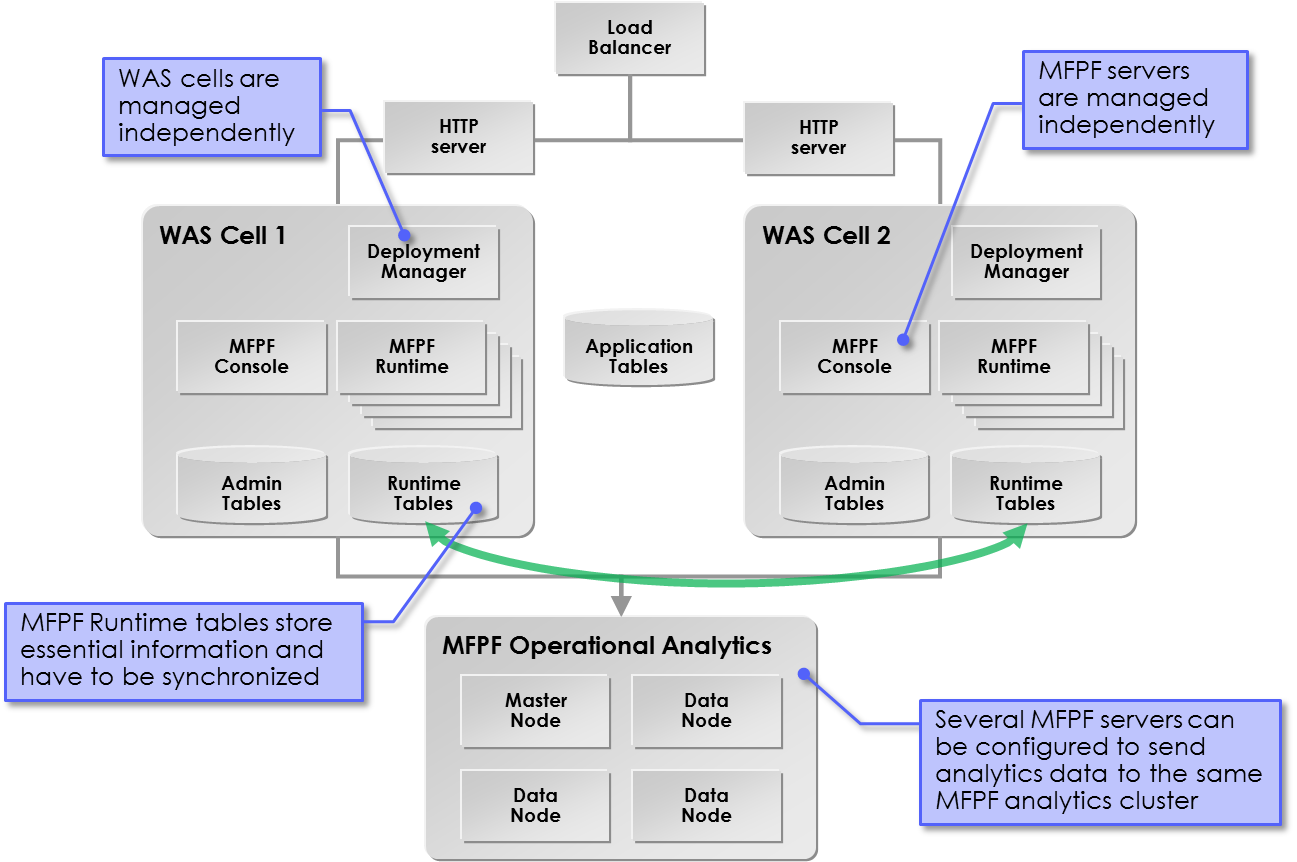
So I designed a solution based on the “disaster recovery site” topology archetype: 2 independent active-active clusters (2 WAS cells) with 2 MFPF runtimes whose internal tables (storing essential information) have to be synchronized.
Having 2 active clusters allows to perform almost all the maintenance activities without stopping the service because one cluster is always available for the production while performing maintenance on the other one deliberately put offline.
MFPF Operational Analytics could be added to this topology because several MFPF servers can be configured to send analytics data to the same analytics cluster. Data can be indexed in 2 ways:
- Together, so all queries reflect all the data that was sent from every MFPF Server
- Separately, adding a tenant, so that they can be searched and viewed separately for each tenant
When I was almost ready to discuss my proposal with the customer, a bank of the group came out with a new request: they would like to have a production-like environment where they want to test new functionalities almost ready for the main stream, but offered to a limited set of customers (the so called Family & Friends. Obviously, the bank doesn’t want to set up and pay for this new environment, but they would like to share as much as possible.
I refined my analysis and demonstrated that my proposed solution could match both usage scenarios:
- The 2 clusters could share the same scope/users and could be active at the same time. This scenario is more focused on performing infrastructure administrative activities without disrupting the service
- Each of the 2 clusters has a different scope or serves specific users and they could be switched at any time to easily offer to a broader audience what was tested on subset of customers.
These 2 scenarios could be combined too, but it requires a good discipline in scheduling the application and infrastructure maintenance activities.
Sometime ago, I read an article about Kano model of customer satisfaction. The Kano model separates features into three broad categories: must-have features (mandatory to be considered by clients), linear or performance features (the more you provide, the more clients would be satisfied), and excitement or “wow” features (provide great client satisfaction).
In this case, to delight my customer I had to stretch the product topologies, but using fully supported capabilities to prevent future problems. A well-engineered solution is worthless without a good day-by-day management discipline: combining these two aspects, IT can provide the best business outcomes and a “wow” feature.
Inclusive terminology note: The Mobile First Platform team is making changes to support the IBM® initiative to replace racially biased and other discriminatory language in our code and content with more inclusive language. While IBM values the use of inclusive language, terms that are outside of IBM's direct influence are sometimes required for the sake of maintaining user understanding. As other industry leaders join IBM in embracing the use of inclusive language, IBM will continue to update the documentation to reflect those changes.