MobileFirst Analytics 프로덕션 클러스터 설정의 우수 사례
improve this page | report issue개요
이 주제에서는 프로덕션 환경에서 Analytics Server를 설정하는 동안 준수할 주의 사항을 포함한 우수 사례 목록에 대해 설명합니다.
MobileFirst Analytics Server - 구성 설정
처음부터 전체 문서 세트를 유지하지 않도록 데이터 제거는 필수적으로 프로덕션 환경에 적용되어야 합니다. 다양한 이벤트 문서에 대해 적절한 TTL 값을 설정하면 Elasticsearch 조회의 검색 범위를 상당히 줄일 수 있습니다. 다음은 MobileFirst Analytics v8.0 Server에 대해 설정하는 TTL 값입니다.
Analytics 이벤트/문서의 TTL 특성
- TTL_PushNotification
- TTL_PushSubscriptionSummarizedHourly
- TTL_ServerLog
- TTL_AppLog
- TTL_NetworkTransaction
- TTL_AppSession
- TTL_AppSessionSummarizedHourly
- TTL_NetworkTransactionSummarizedHourly
- TTL_CustomData
- TTL_AppPushAction
- TTL_AppPushActionSummarizedHourly
- TTL_PushSubscription
사용법 예:
<jndiEntry jndiName="analytics/TTL_AppLog" value= '"20d"' />
TTL 값은 문자열 리터럴이어야하며 작은따옴표로 묶어서 전달되어야 합니다.
MobileFirst Analytics Server - 토폴로지
다중 노드 Analytics 클러스터
- 노드 앞에 로드 밸런서를 설치하여 분석 계층이 노드 전체에 균등한 로드가 제공되도록 하는 것이 중요합니다.
- 로드 밸런서를 사용하지 않을 때 두 개의 노드를 가진 분석 클러스터에서는 MobileFirst 서버의 데이터를 승인하는 데 사용되지 않는 노드의 Analytics Console을 구성하거나 사용하는 것이 좋습니다.
예:
Analytics Server에 대해 두 개의 노드가 있다고 가정합니다. 이러한 경우, 분석용 MobileFirst Server 구성에 대한 권장사항은 다음과 같습니다.
권장
mfp.analytics.url -> http://node1:9080/analytics-service/rest
mfp.analytics.console.url -> http://node2:9080/analytic/console
권장하지 않음:
mfp.analytics.url -> http://node1:9080/analytics-service/rest
mfp.analytics.console.url -> http://node1:9080/analytic/console
이를 통해 사용자는 Analytics Console을 볼 때 노드의 로드를 줄일 수 있습니다.
MobileFirst Analytics Server - 성능 튜닝
운영 체제 튜닝
- 허용되는 열린 파일 디스크립터 수를 32k 또는 64k로 늘리십시오.
- 가상 메모리 맵 개수를 늘리십시오.
참고: 운영 체제에 해당하는 문서를 확인하십시오.
애플리케이션 서버 튜닝
WebSphere Application Server v8.5.5.6 Liberty 프로파일 또는 이전 버전을 사용하는 경우, JVM 스레드 풀 크기 설정을 명시적으로 조정해야 합니다.
이로 인해 많은 사용자는 실행자가 교착 상태에 빠지지 않도록 실행자의 coreThreads 값을 높은 숫자로 설정했습니다. 하지만 v8.5.5.6에서 자동 튜닝 알고리즘은 교착 상태를 공격적으로 대처하도록 수정되었습니다. 이제 실행자가 교착 상태에 빠지는 것은 거의 불가능합니다. 따라서 과거에 실행자가 교착 상태를 피하기 위해 수동으로 coreThreads를 설정한 경우, v8.5.5.6으로 이동하면 기본값으로 되돌리는 것을 고려할 수 있습니다.
예:
<executor name="LargeThreadPool" id="default" coreThreads="200" maxThreads="400" keepAlive="60s" stealPolicy="STRICT" rejectedWorkPolicy="CALLER_RUNS"/>
Analytics 튜닝
- Java Xms 및 Xmx 모두 동일하게 설정(최소 및 최대)해야 합니다.
- JVM당 허용되는 최대 힙 크기 <= RAM 크기/2.
- 기본 샤드 수 = Analytics 클러스터의 노드 수.
- 샤드당 복제본 수 >= 2.
참고: 노드가 하나뿐이면 복제본이 필요하지 않습니다.
Elasticsearch 튜닝
Elasticsearch 튜닝은 별도 YAML 파일(예: elasticsearchconfig.yml로 이름이 지정될 수 있음)에서 실행할 수 있고, 이 파일의 경로는 Analytics Server 구성에서 구성할 수 있습니다(JNDI 특성 사용).
특성 이름: * analytics/settingspath
값: *<path_to_the_ES_config_yml>
해당 값을 .yml 파일에 추가하고 JNDI 항목을 사용하여 액세스하여 Elasticsearch 튜닝 매개변수를 적용하십시오.
Elasticsearch 튜닝 매개변수는 환경의 기본 튜닝으로 고려되며 인프라 자원을 기반으로 추가로 조정할 수 있습니다.
-
indices.fielddata.cache.size 값 설정
예:
indices.fielddata.cache.size: 35%참고: analytics/indices.fielddata.cache.size를 주의하여 사용하십시오. 이 값을 늘리면 OutofMemory가 발생할 수 있으므로 높은 값으로 늘리지 마십시오. 분석 플랫폼에서 사용되는 기본 기술은 여러 필드 값을 메모리에 로드하여 해당 문서에 대한 보다 빠른 액세스를 제공합니다. 이를 필드 캐시라고 합니다. 기본적으로 필드 캐시에 의해 메모리에 로드되는 데이터의 양에는 제한이 없습니다. 필드 캐시가 너무 커지는 경우, 이에 따라 메모리 부족 예외가 발생하고 분석 플랫폼의 충돌(crash)이 발생할 수 있습니다.
-
indices.fielddata.breaker.limit의 값을 설정하십시오.
indices.fielddata.breaker.limit를 indices.fielddata.cache.size보다 큰 값으로 설정하십시오.
따라서 캐시 크기가 35%인 경우 차단기 한계를 캐시 크기보다 큰 값으로 설정하십시오.
-
indices.fielddata.cache.expire의 값을 설정하십시오.
이 값은 Elasticsearch 캐시의 만료 시간을 설정하여 캐시가 제한없이 증가하고 힙을 채우는 것을 방지합니다.
indices.fielddata.cache.expire
특정 시간 동안 사용하지 않으면 필드 데이터가 만료되는 시간 기반 설정입니다. 기본값은 -1입니다. 예를 들어, 5분 만료일 경우 5m으로 설정할 수 있습니다.
-
Analytics의 기본 설정은 데이터를 제거하지 “않는” 것입니다.
데이터가 제거되도록 TTL을 적절하게 구성하십시오. 그렇지 않으면, 데이터 저장소가 무제한으로 증가할 수 있습니다.
MobileFirst Analytics Server - 주의할 사항
- 분석 노드가 실행 중일 때 analyticsData 디렉토리를 지우지 마십시오.
- 다중 노드 클러스터에서는 동일한 노드를 사용하여 이벤트를 분석 클러스터로 푸시하고 콘솔에 액세스하지 마십시오. 분석 클러스터 앞에서 로드 밸런서를 사용하는 것이 가장 좋습니다.
- Analytics 클러스터에 대해 기타 Application Server 클러스터링 방법론을 사용하지 마십시오. 기본 Elasticsearch에서는 노드 발견 메커니즘을 사용하여 자체적으로 클러스터를 작성합니다.
- IBM WebSphere Application Server 전체 프로파일 (또는) IBM WebSphere Application Server Network Deployment에서 Analytics에 대해 오픈 JDK(또는 Sun Java)를 사용하지 마십시오.
- Analytics 최소/최대 힙 크기를 노드의 RAM 크기의 절반보다 큰 값으로 늘리지 마십시오. 예를 들어, RAM 크기가 16GB인 노드의 경우 분석을 위해 허용되는 최대 힙 크기는 8GB입니다.
- 분석 클러스터 이름(analytics/clustername JNDI 특성)의 경우 고유한 클러스터 이름을 사용하십시오. 기본 이름 worklight를 사용하지 마십시오.
MobileFirst Analytics Server - SDK 문제
1. Cordova 애플리케이션은 AppSession 캡처를 사용하려면 라이프사이클 이벤트용 네이티브 플랫폼에서 초기화해야 합니다.
MobileFirst Platform Foundation v8.0에서 앱이 백그라운드에서 포그라운드로 이동하면 앱 세션은 증가/기록됩니다.
AppSessions 캡처는 라이프사이클 이벤트용 리스너를 추가하여 사용할 수 있습니다. 네이티브 SDK에서 이러한 리스너를 추가하는 데 적합한 API를 제공합니다. 그러나 Cordova의 경우 이러한 라이프사이클 이벤트 리스너를 추가하기 위한 JavaScript API가 없습니다. 대신 Cordova애플리케이션에서도 네이티브 플랫폼 API를 사용하여 리스너를 추가해야 합니다.
문서에서 다음과 같이 발췌하십시오.
Analytics SDK가 구성되고 나면 사용자 디바이스에서 앱 세션 기록이 시작됩니다. MobileFirst Analytics에서 세션은 앱이 포그라운드에서 백그라운드로 이동할 때 기록되며, Analytics Console에서 세션을 작성합니다. 디바이스가 세션을 기록하도록 설정되어 있으면 사용자가 데이터를 전송하는 즉시 아래에 표시된 대로 데이터로 채워진 Analytics Console을 볼 수 있습니다.
예를 들어, iOS 플랫폼(iOS)의 Cordova 앱의 경우 AppDelegate.m에 다음을 추가해야 합니다.
[[WLAnalytics sharedInstance] addDeviceEventListener:LIFECYCLE];
[[WLAnalytics sharedInstance] send];
2. Analytics Console의 사용자 정의 데이터 보기
Analytics 클라이언트 SDK API를 사용하여 Analytics Server에 전송된 사용자 정의 데이터를 신속하게 찾으려면 다음 단계를 수행할 수 있습니다.
Analytics Console > 대시보드 > 사용자 정의 차트 > 사용자 정의 차트 작성으로 이동
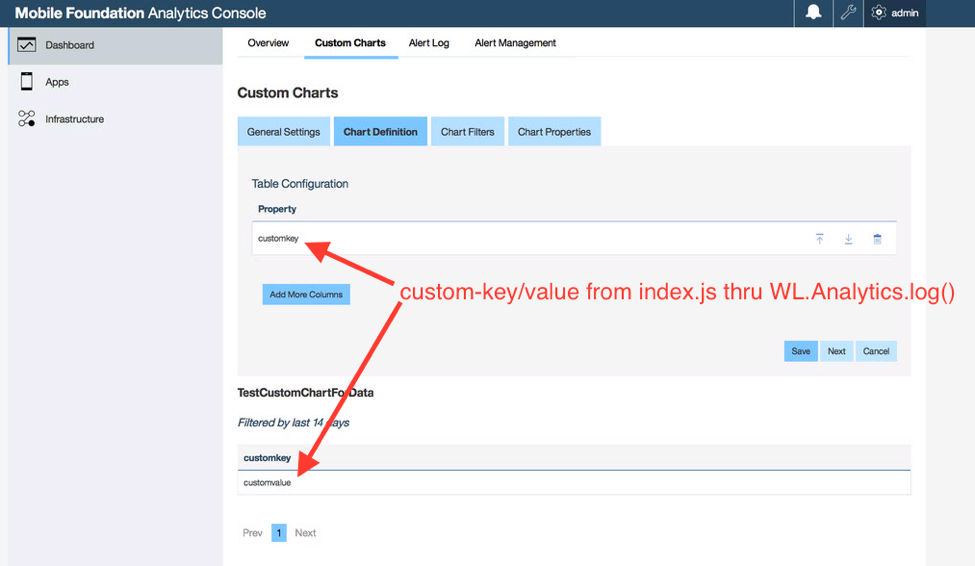
자세한 정보는 문서 여기를 참조하십시오.
MobileFirst Analytics Server - 문제점 해결 단계
- 고객 환경 버전:
OS, JDK/JRE, AppServer, MobileFirst Platform Foundation 버전 및 MobileFirst Platform Foundation 빌드 버전을 포함하여 전체 소프트웨어 스택의 세부사항을 수집하십시오. - 환경 상세 정보를 IBM MobileFirst Analytics 소프트웨어 호환성 매트릭스/요구사항과 비교하십시오.
- Analytics 토폴로지 & 사용된 하드웨어 스펙을 수집하십시오.
- 성능 튜닝이 수행되었는지 확인하십시오(성능 문제가있는 경우).
- Analytics 통합 구성을 확인하려면 MobileFirst Platform Foundation Server의
server.xml(Liberty) 및 JNDI 환경 항목/특성(WAS 전체 프로파일/ND)을 수집하십시오. - Analytics 관리 콘솔의 스크린 샷을 수집하십시오.
- Analytics 통합 구성을 확인하려면 Analytics의
server.xml(Liberty) 및 JNDI 환경 항목/특성(WAS 전체 프로파일/ND)을 수집하십시오. - 다음 REST API의 출력을 수집하십시오(Analytics 문제점 해결을 위한 중요 명령 & API 섹션에 나열됨).
문제점 해결을 위한 유틸리티
다음은 elasticsearch 인덱스, 데이터/샤드 할당 등을 시각화하고 관리하는 데 효과적으로 사용할 수 있는 오픈 소스 도구입니다.
Analytics 문제점 해결을 위한 중요 명령 & API
cURL을 사용하여 다음 REST API를 실행하여 클러스터/샤드 /인덱스에 대한 다양한 정보를 식별하는 응답을 캡처합니다.
http://<es_node>:9500/_cluster/health
http://<es_node>:9500/_cluster/stats
http://<es_node>:9500/_cat/shards
http://<es_node>:9500/_node/status
http://<es_node>:9500/_cat/indices
참조
- MobileFirst Analytics - Quick & Dirty clusters
- MobileFirst Analytics - Planning for Production
- MobileFirst Analytics – Installation Guide
- Setting JNDI property for Mobile Analytics Time To Live(TTL) value as days in Liberty Profile
Inclusive terminology note: The Mobile First Platform team is making changes to support the IBM® initiative to replace racially biased and other discriminatory language in our code and content with more inclusive language. While IBM values the use of inclusive language, terms that are outside of IBM's direct influence are sometimes required for the sake of maintaining user understanding. As other industry leaders join IBM in embracing the use of inclusive language, IBM will continue to update the documentation to reflect those changes.